真的太可爱了






朋友们,浏览器这次真的要进化成智能体了!近期,Chrome 悄然上线了Skills功能,直接让浏览器迈入 Agent 化发展的关键阶段。这意味着,你的浏览器不再只是浏览网页的工具,更像一位随时待命的智能助手。
Chrome上线Skills
浏览器原地变龙虾
谷歌近期正式发布Gemini Skills,核心作用很简单:帮你把优质的 AI 提示词(prompt)保存为专属技能,下次遇到同类场景,一键即可调用,无需反复手动输入。
使用体验上,它支持跨设备同步。登录 Google 账号后,你在办公电脑保存的技能,回家打开 Chrome 就能直接使用。
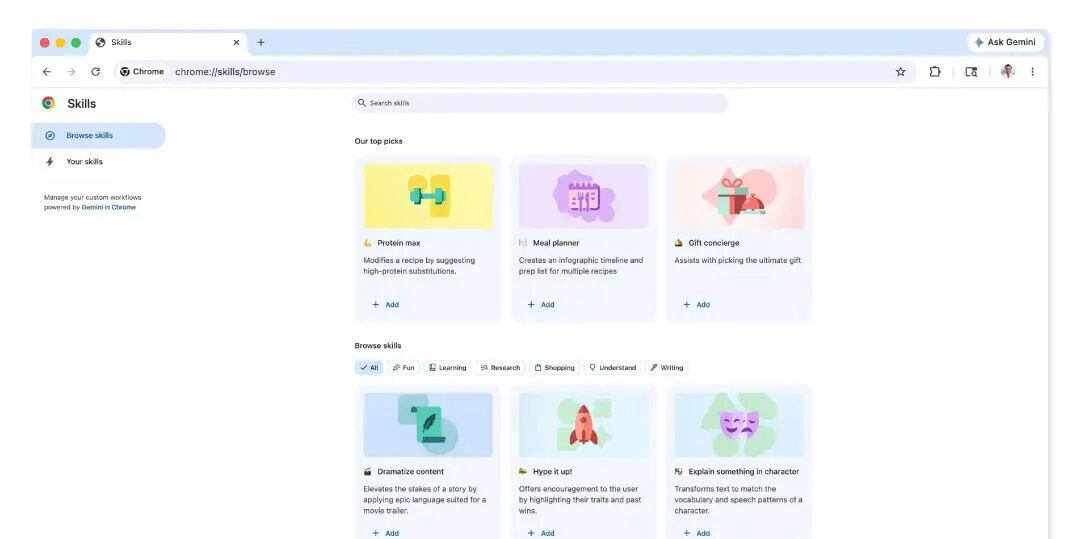
具体操作也很便捷:在 Gemini 对话框输入斜杠「/」,或点击右侧加号按钮,选择已保存的技能,就能一键执行。

此外,谷歌还内置了50 + 预设技能,覆盖食谱营养计算、护肤品成分解析、YouTube 视频总结等常用场景。不满意可自行修改,保存后可重复使用。
但以前要在龙虾或者Claude Code里用,难免让人有些望而却步。如今直接集成在浏览器中,上手门槛可以说是彻底归零。
而且,Skills已在桌面端Gemini in Chrome逐步灰度上线,保存的技能会同步至所有已登录的 Chrome 桌面设备。管理入口:在 Gemini in Chrome 输入 「/」,点击指南针图标即可进入。
目前,该功能仍处于初期阶段,若后续开放技能社区分享、优化跨设备同步能力,潜力会更大。使用时需注意网络环境要求。
2026.04.16测试可用
import requests
from DrissionPage import ChromiumPage
import pandas as pd
import time
from datetime import datetime
driver_dp = ChromiumPage()
driver_dp.listen.start('x/v2/reply/wbi/main')
driver_dp.get(
'此处粘贴视频链接')
time.sleep(5)
driver_dp.scroll.down(400)
time.sleep(3)
all_comments = []
all_responses = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0',
'cookie': "此处粘贴自己的cookie",
'origin': 'https://www.bilibili.com',
'referer': 'https://www.bilibili.com/bangumi/play/ep125985',
}
def get_secondary_comments(root_rpid, total_count):
comments_per_page = 10
total_pages = (total_count + comments_per_page - 1) // comments_per_page
all_replies = []
print(f"主评论 {root_rpid} 共有 {total_count} 条回复,需要分 {total_pages} 页获取")
for current_page in range(1, total_pages + 1):
url = f'https://api.bilibili.com/x/v2/reply/reply?oid=115983628897173&type=1&root={root_rpid}&ps={comments_per_page}&pn={current_page}&web_location=666.25'
try:
response = requests.get(url, headers=headers).json()
if response['code'] == 0:
replies = response['data']['replies']
if replies:
all_replies.extend(replies)
print(f" 已获取第 {current_page}/{total_pages} 页,获得 {len(replies)} 条回复")
else:
print(f" 第 {current_page} 页无数据")
else:
print(f" 获取第 {current_page} 页失败: {response['message']}")
except Exception as e:
print(f" 获取第 {current_page} 页时出错: {str(e)}")
time.sleep(0.5)
return all_replies
def scroll_to_bottom():
print("开始滚动页面加载更多评论...")
last_height = driver_dp.run_js('return document.body.scrollHeight;')
max_scroll_attempts = 20
scroll_attempts = 0
while scroll_attempts < max_scroll_attempts:
driver_dp.scroll.to_bottom()
time.sleep(3)
new_height = driver_dp.run_js('return document.body.scrollHeight;')
if new_height == last_height:
print("已滚动到底部,没有新内容加载")
scroll_attempts += 1
else:
print(f"页面高度增加: {new_height - last_height}px")
last_height = new_height
scroll_attempts = 0
try:
res = driver_dp.listen.wait(timeout=5)
if res:
all_responses.append(res)
print(f"获取到第 {len(all_responses)} 页评论数据")
else:
print("未监听到新评论接口响应")
except:
print("等待评论接口超时")
if scroll_attempts >= 3:
print("连续多次滚动无新内容,停止滚动")
break
print(f"共收集到 {len(all_responses)} 页评论数据")
try:
res = driver_dp.listen.wait(timeout=15)
if res:
all_responses.append(res)
print("获取到第一页评论数据")
else:
print("未获取到第一页评论数据")
except:
print("等待第一页评论超时")
scroll_to_bottom()
print("开始处理评论数据...")
for response in all_responses:
try:
if hasattr(response, 'response') and hasattr(response.response, 'body'):
body = response.response.body
if 'data' in body and 'replies' in body['data']:
for reply in body['data']['replies']:
content = reply['content']['message']
ctime = datetime.fromtimestamp(reply['ctime']).strftime('%Y-%m-%d %H:%M:%S')
like = reply['like']
rpid = str(reply['rpid'])
name = reply['member']['uname']
sex = reply['member']['sex']
count = reply['count']
all_comments.append({
'类型': '主评论',
'评论ID': rpid,
'内容': content,
'时间': ctime,
'点赞数': like,
'用户名': name,
'性别': sex,
'回复数': count,
'回复对象': ''
})
print(f"处理主评论 {rpid} ({name}),有 {count} 条回复")
if count > 0:
secondary_comments = get_secondary_comments(rpid, count)
for reply in secondary_comments:
reply_content = reply['content']['message']
reply_ctime = datetime.fromtimestamp(reply['ctime']).strftime('%Y-%m-%d %H:%M:%S')
reply_like = reply['like']
reply_rpid = str(reply['rpid'])
reply_name = reply['member']['uname']
reply_sex = reply['member']['sex']
all_comments.append({
'类型': '二级评论',
'评论ID': reply_rpid,
'内容': reply_content,
'时间': reply_ctime,
'点赞数': reply_like,
'用户名': reply_name,
'性别': reply_sex,
'回复数': 0,
'回复对象': rpid
})
else:
print("响应中缺少评论数据")
else:
print("无效的响应对象")
except Exception as e:
print(f"处理响应时出错: {str(e)}")
if all_comments:
df = pd.DataFrame(all_comments)
columns = ['类型', '评论ID', '回复对象', '用户名', '性别', '内容', '时间', '点赞数', '回复数']
df = df[columns]
df['评论ID'] = df['评论ID'].astype(str)
df['回复对象'] = df['回复对象'].astype(str)
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f'哔哩哔哩评论_{timestamp}.xlsx'
with pd.ExcelWriter(filename, engine='openpyxl') as writer:
df.to_excel(writer, index=False)
worksheet = writer.sheets['Sheet1']
for cell in worksheet['B']:
cell.number_format = '@'
for cell in worksheet['C']:
cell.number_format = '@'
print(f"所有评论已保存到文件: {filename}")
else:
print("未获取到任何评论数据")
driver_dp.quit()






